People often describe downloadable AI models as “open source.”
Sometimes that is accurate. Often it is not.
In AI, there is an important distinction between open weights and open source. The difference is not pedantic. It affects what you can inspect, what you can reproduce, what you can modify, and what risks you take when building on top of a model.
The Short Version
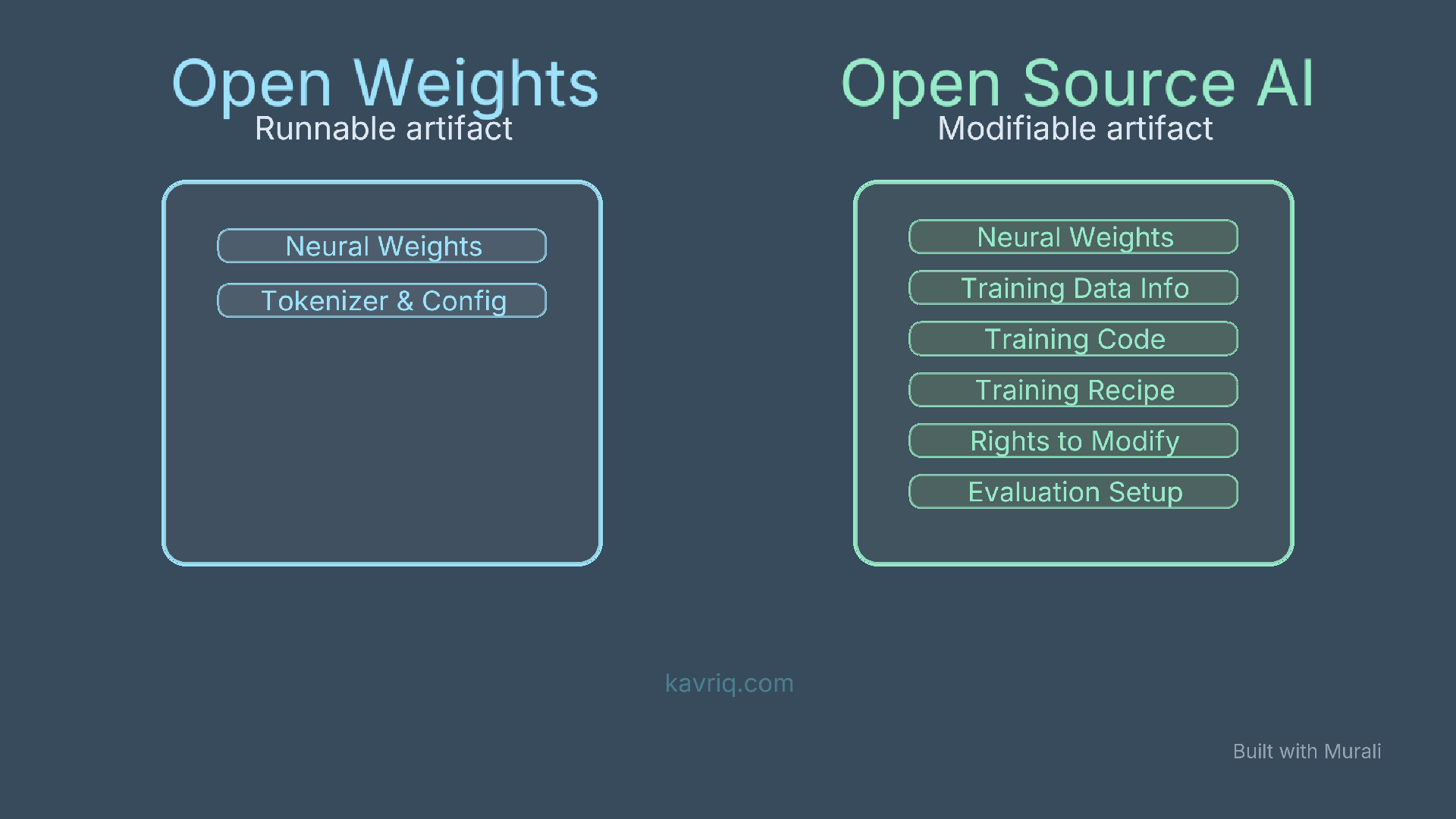
An open-weight model gives you access to the trained parameters of the model. You can usually download the model, run it locally, fine-tune it, quantize it, or deploy it on your own infrastructure, depending on the license.
An open source AI system goes further. It should provide the freedoms to use, study, modify, and share the system, plus enough access to the preferred form for making modifications.
For machine learning systems, that preferred form is not only the final weights. It also includes information about the training data, the code used to process data and train the model, the inference code, model architecture, and the parameters needed to understand and modify the system.
That is the core distinction:
| Term | What you usually get | What may still be missing |
|---|---|---|
| Open weights | Model weights, config, tokenizer, inference examples | Training data details, training code, filtering pipeline, full reproducibility |
| Open source AI | Weights, code, data information, modification rights, sharing rights | Usually less common, harder to satisfy fully |
Why Weights Alone Are Not the Source
In traditional software, source code is the preferred form for modification. If you have the source code, build instructions, and an open source license, you can inspect how the program works, change it, rebuild it, and share your changes.
AI systems are different.
The final model weights are an output of training. They are incredibly useful, but they are not the full recipe. They do not tell you exactly:
- what data was used
- how the data was filtered
- how synthetic data was generated
- what safety tuning was applied
- what training code and hyperparameters were used
- what evaluations shaped the final release
- what content was excluded
- what licensing constraints apply to downstream use
You can modify open weights by fine-tuning or merging adapters, but you usually cannot recreate the original model from first principles. You also cannot fully inspect the social, legal, and technical choices embedded in the training process.
That is why calling every downloadable model “open source” blurs an important engineering boundary.
What Open Weights Are Good For
Open-weight models are still extremely valuable.
They let developers:
- run models offline
- avoid sending private prompts to a hosted API
- control latency and deployment environment
- fine-tune or adapt a model for a domain
- quantize models for laptops, workstations, and edge devices
- inspect behavior more directly than with closed APIs
- build local agents with tools like Ollama, llama.cpp, vLLM, and SGLang
For local agentic AI, open weights are often exactly what you need. If the goal is to build a private coding agent, document assistant, workflow runner, or local research tool, downloadable weights matter enormously.
But they do not automatically make the model open source.
What Open Source AI Requires
The Open Source Initiative’s Open Source AI Definition 1.0 frames open source AI around four freedoms: use, study, modify, and share. It also says that users need access to the preferred form for making modifications.
For AI, that preferred form includes three broad categories:
- Data information: enough detail about the training data for a skilled person to understand and build a substantially equivalent system
- Code: the code used to train and run the system, including data processing, training, validation, tokenizers, inference, and architecture
- Parameters: the model weights and related configuration
This is a higher bar than simply publishing a .safetensors file.
It is also why some models are better described as open-weight or source-available, even when they are easy to download and powerful in practice.
A Practical Test for Model Cards
When you see a model advertised as open, ask four questions.
1. Can I download and run the weights?
If yes, the model is at least open-weight in a practical sense.
But check the license. Some model licenses restrict commercial use, large-scale deployment, certain use cases, or redistribution. A model can be downloadable and still not open source.
2. Can I inspect the training process?
Look for training code, data processing code, tokenizer training details, hyperparameters, evaluation setup, and post-training steps.
If those are missing, the model is not fully transparent.
3. Do I know what data shaped the model?
You may not need every raw training example, but serious openness requires meaningful data information: provenance, selection criteria, filtering, labeling, synthetic generation, and known exclusions.
Without that, you cannot properly reason about copyright risk, domain coverage, bias, contamination, or reproducibility.
4. Can I modify and share without asking permission?
Open source is not only about visibility. It is also about permission.
If the license gives you broad rights to use, modify, and redistribute, that is closer to open source. If it only allows narrow use under special terms, it is something else.
Why This Matters for Engineers
The distinction changes how you should think about adoption.
For a hobby project or private local agent, an open-weight model may be enough. You care about whether it runs on your machine, follows tool instructions, handles your context window, and has acceptable latency.
For a production system, the questions become sharper:
- Can we use this commercially?
- Can we redistribute a fine-tuned version?
- Can we explain where the model came from?
- Can we audit the training pipeline?
- Can we comply with customer or regulatory requirements?
- Can we replace or reproduce the model if the vendor changes terms?
Open weights reduce dependency on hosted APIs. Open source AI reduces dependency on hidden training and licensing decisions.
Those are related, but not identical.
Examples of Careful Language
Instead of saying:
This is an open source model.
Say one of these when it is more accurate:
- This is an open-weight model.
- The weights are publicly available.
- The model is source-available under a custom license.
- The model can be run locally, but the training data and full pipeline are not fully open.
- The model appears to meet open source AI criteria because it provides weights, code, data information, and modification rights.
Careful language helps users make better decisions.
The Bottom Line
Open weights are a major reason local AI is becoming practical. They let you run strong models on your own hardware and build private systems without depending entirely on cloud APIs.
But open weights are not the same as open source AI.
If you can download the final model but cannot inspect the training process, data provenance, or full modification path, you have a useful open-weight release, not necessarily an open source AI system.
For most builders, the right question is not “Is this model open?” It is more specific:
Open in what sense, under what license, with which components, and for which use case?
That question will save you from a lot of confusion.